Hey there! 👋
If you found this page on Google, chances are that you are trying to fix the FailedGetResourceMetric error in HPA. If that's the case, you are in the right place!
In case you're new to HPA (HorizontalPodAutoscaler), we also have a short introduction to HPA that you may want to check out first.
How to see the FailedGetResourceMetric error
Before diving into the fixes, here is how you can confirm you are seeing this error. Run the following command and look at the Conditions section in the output:
kubectl describe hpa <hpa-name>
You should see something like this under Conditions:
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale ...
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: ...There are a few different reasons why this error can happen, so let's go through each one.
1. Missing Metrics
failed to get cpu utilization: unable to get metrics for resource cpu:
no metrics returned from resource metrics APIThis is probably the most common cause of the error, but also the easiest to fix.
To decide whether Kubernetes needs to create more replicas of a service, the Horizontal Pod Autoscaler (HPA) needs to know the current CPU and memory usage of the pods it is managing. The error above means that it cannot find any metrics for the service it is trying to scale.
metrics-server is the most popular solution that collects resource metrics from Kubelets and exposes them in the Kubernetes API server through the Metrics API for use by HPA and Vertical Pod Autoscaler (VPA).
Most managed Kubernetes cluster services (GKE, EKS, AKS, etc.) already have metrics-server or an equivalent installed by default. However, if you are self-hosting a Kubernetes cluster, you may need to install it manually.
To install it, you can simply run:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
This will install all the necessary components to get metrics-server up and running. It may take a minute or two to collect the first metrics, but you can validate that it is working by running:
kubectl top pods
Yay! 🎉 You should now be able to see the CPU and memory usage of your pods, as well as auto-scale them using HPA and VPA!
2. Missing Resource Requests
Now that you have metrics-server up and running, you may still see the following errors:
the HPA was unable to compute the replica count: failed to get cpu utilization:
missing request for cpu
the HPA was unable to compute the replica count: failed to get memory utilization:
missing request for memory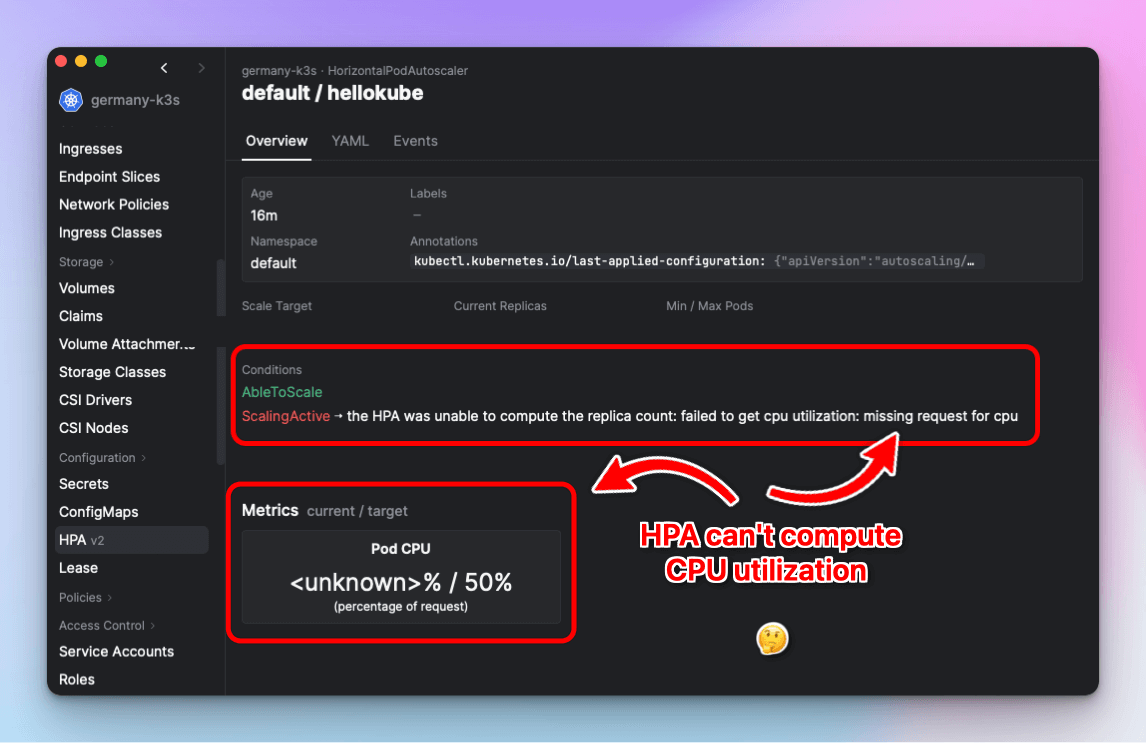
Screenshot of Aptakube setting resource requests on target scaled object.
Let's take a step back to understand what is going on.
When you create an HPA to scale based on CPU/Memory averageUtilization, the HPA needs to know the current usage and the requested resources across all matching pods.
- Current Usage: Collected by metrics-server (or another metrics service like Prometheus) and made available via the Metrics API.
- Requested Resources: Sum of the resource requests on each container in the matching pods.
It is common to think that HPA uses resource limits to calculate the average utilization, but that is not correct. HPA uses resource requests instead of limits, which is what this error is telling you.
In summary, some or all containers in your pods are missing resource requests. To fix this, find the target scaled object (Deployment, StatefulSet, etc.) and set the resource requests on the containers that are missing them.
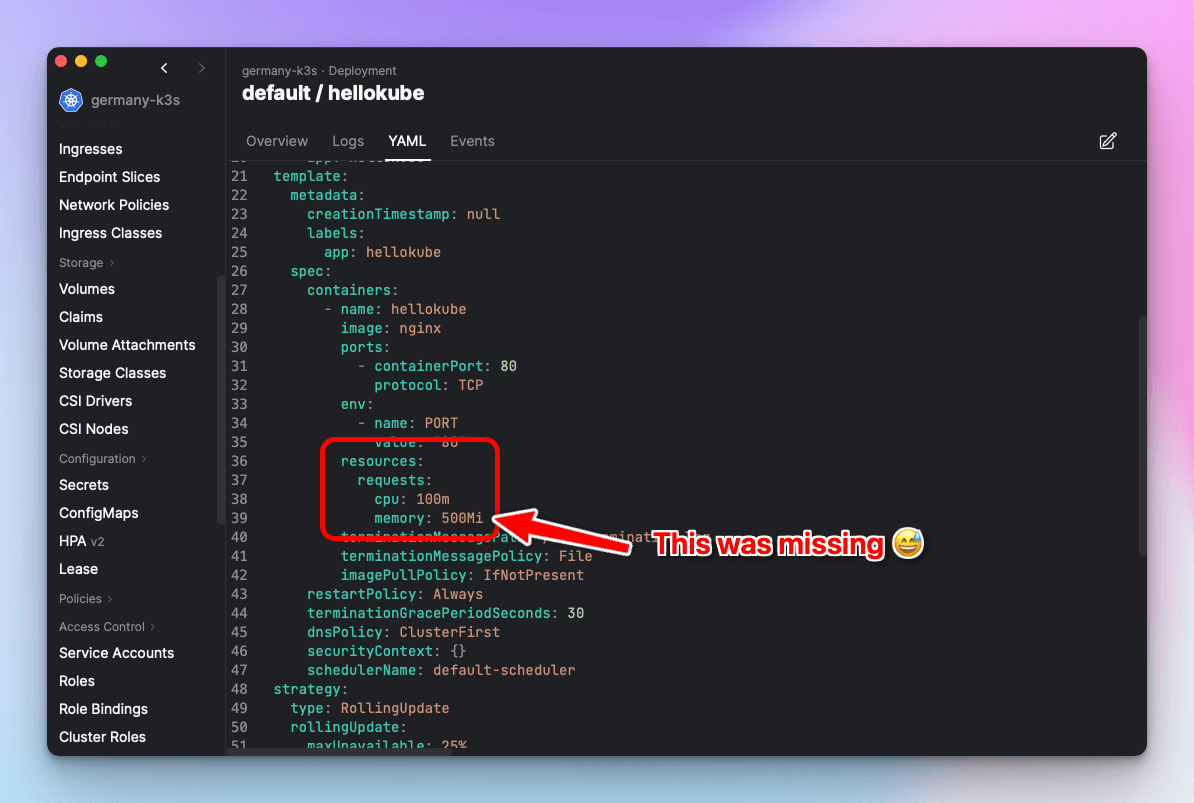
Screenshot of Aptakube showing HPA errors.
Important: This requirement also applies to sidecars that may be automatically injected and are not directly visible in the source YAML manifest. This is very common with service meshes like Linkerd and Istio. If you are using a service mesh, make sure that you also add resource requests to the sidecar containers. This is often done by adding annotations to the target scale object — check the documentation for your specific service mesh.
3. Bonus: Scaling Limited by Maximum Replica Count
This one is more self-explanatory than the previous cases and is not directly related to FailedGetResourceMetric, but it is worth mentioning.
You may see the following condition on your HPA:
ScalingLimited ➝ the desired replica count is more than the maximum replica countThis means that Kubernetes is trying to scale a service to more replicas than the maximum allowed by the HPA.
Whether this is a problem depends on your use case.
If you are seeing performance or availability degradation in your service, you may want to increase the maxReplicas value in your HPA to allow for a higher replica count. If you are not noticing any degradation, investigate why Kubernetes is trying to scale beyond the maximum and consider tuning your resource requests or HPA metric targets accordingly.
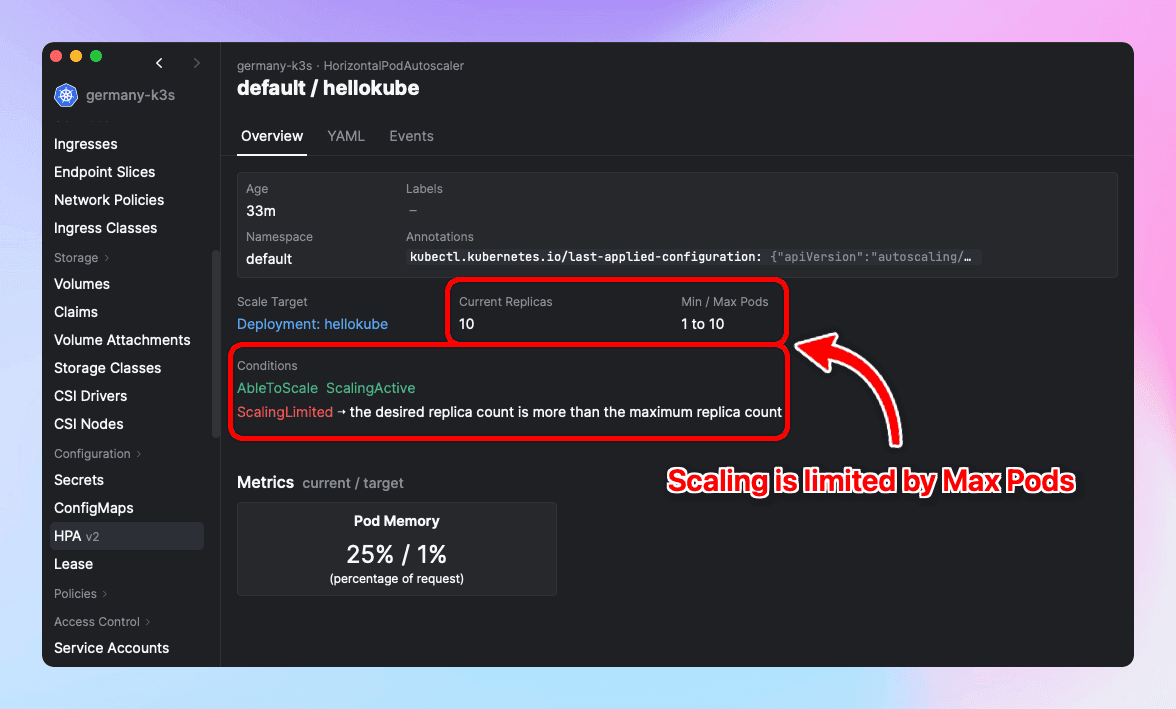
Screenshot of Aptakube showing a HPA with limited scaling due to max pods.
Conclusion
To summarize, the FailedGetResourceMetric error in Kubernetes HPA is most commonly caused by:
- No metrics-server installed — Install metrics-server (or an equivalent like prometheus-adapter) so that the HPA can read pod resource usage.
- Missing resource requests on containers — Set CPU and/or memory
requestson all containers (including sidecar containers) in the pods targeted by the HPA. - ScalingLimited — If the HPA is hitting the
maxReplicascap and your service is degraded, increasemaxReplicasor tune your resource requests and metric targets.
Hopefully this guide helped you get your auto-scaling back on track! If you want to learn more about HPA, check out our complete guide to HorizontalPodAutoscaler.

